
레디스란?
레디스는 Remote Dictionary Server의 약자로 모든 데이터를 디스크가 아닌 메모리에 저장하는 in-memory 데이터베이스이자, key-value 구조의 저장소이다.

(이미지 출처: ByteByteGo)
위의 이미지처럼 메모리 상에서 운영되는 NoSQL 데이터베이스이기 때문에 빠른 입출력이 가능하지만 장애가 발생하면 모든 데이터를 잃을 위험이 있다.
레디스의 저장소 구현 코드
레디스의 핵심 구조는 다음과 같이 계층적으로 구성되어 있으며, 오픈소스이기 때문에 코드를 보면서 실제 구현을 확인할 수 있다.

dict
dict는 dictType과 dictEntity를 포함하고 있는 해시 테이블이다.
// redis/deps/hiredis/dict.h
typedef struct dict {
dictEntry **table;
dictType *type;
unsigned long size;
unsigned long sizemask;
unsigned long used;
void *privdata;
} dict;
dictEntity
dictEntity는 개별 key-value 값을 저장하고 다음 key-value를 나타내는 포인터를 가지고 있다.
// redis/deps/hiredis/dict.h
typedef struct dictEntry {
void *key; // 키를 저장
void *val; // 값을 저장
struct dictEntry *next;
} dictEntry;
dictType
dictType은 해시 테이블의 동작을 정의하는 함수를 정의하고, 다양한 데이터 구조를 지원한다.
// redis/deps/hiredis/dict.h
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // 해시 값을 계산하는 함수
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
아래의 set 딕셔너리, string set 딕셔너리 처럼 해시 함수의 종류 같은 조건에 따라서 다형적으로 변한다.
dictType setDictType = {
dictSdsHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictSdsKeyCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL, /* val destructor */
NULL, /* allow to expand */
.no_value = 1, /* no values in this dict */
.keys_are_odd = 1 /* an SDS string is always an odd pointer */
};
dictType stringSetDictType = {
dictCStrCaseHash, /* hash function */
NULL, /* key dup */
NULL, /* val dup */
dictCStrKeyCaseCompare, /* key compare */
dictSdsDestructor, /* key destructor */
NULL, /* val destructor */
NULL /* allow to expand */
};

자료구조에 따라 작업의 속도가 달라지는데, Strings의 경우 O(1), Sorted Sets의 경우 O(log N), Lists의 경우 O(n)의 속도를 보여준다. 읽기와 쓰기, 해싱, 집합 정렬 연산 등은 CPU에서 이루어지는데 간단한 연산이 대부분이기 때문에 빠른 속도로 처리가 가능하다.
kvstore
kvsotre는 dict를 포함하고 있으며, 해시 테이블의 개수, 현재 리사이징 하고 있는지 여부, 총 키의 개수 등 해시테이블과 관련된 메타데이터를 관리한다.
// redis/src/kvtore.c
struct _kvstore {
int flags;
dictType dtype;
dict **dicts;
long long num_dicts;
long long num_dicts_bits;
list *rehashing; /* List of dictionaries in this kvstore that are currently rehashing. */
int resize_cursor; /* Cron job uses this cursor to gradually resize dictionaries (only used if num_dicts > 1). */
int allocated_dicts; /* The number of allocated dicts. */
int non_empty_dicts; /* The number of non-empty dicts. */
unsigned long long key_count; /* Total number of keys in this kvstore. */
unsigned long long bucket_count; /* Total number of buckets in this kvstore across dictionaries. */
unsigned long long *dict_size_index; /* Binary indexed tree (BIT) that describes cumulative key frequencies up until given dict-index. */
size_t overhead_hashtable_lut; /* The overhead of all dictionaries. */
size_t overhead_hashtable_rehashing; /* The overhead of dictionaries rehashing. */
};
redisDb
redisDb는 kvstore를 포함하고 있으며 데이터베이스 id, 평균 TTL 등의 전체 데이터베이스를 관리를 담당한다.
// redis/src/server.h
typedef struct redisDb {
kvstore *keys; /* The keyspace for this DB */
kvstore *expires; /* Timeout of keys with a timeout set */
ebuckets hexpires; /* Hash expiration DS. Single TTL per hash (of next min field to expire) */
dict *blocking_keys; /* Keys with clients waiting for data (BLPOP)*/
dict *blocking_keys_unblock_on_nokey; /* Keys with clients waiting for
* data, and should be unblocked if key is deleted (XREADEDGROUP).
* This is a subset of blocking_keys*/
dict *ready_keys; /* Blocked keys that received a PUSH */
dict *watched_keys; /* WATCHED keys for MULTI/EXEC CAS */
int id; /* Database ID */
long long avg_ttl; /* Average TTL, just for stats */
unsigned long expires_cursor; /* Cursor of the active expire cycle. */
list *defrag_later; /* List of key names to attempt to defrag one by one, gradually. */
} redisDb;
I/O 멀티플렉싱 싱글 스레드 모델

(이미지 출처: ByteByteGo)
싱글 스레드 - 이벤트 루프
레디스는 I/O 작업을 기다리며 대기하는 하나의 이벤트 루프를 사용한다.
한개의 작업이 끝나기 전까지는 다른 작업을 할 수 없기 때문에 성능이 저하될 것이라고 예상하기 쉽지만 다음의 이유로 레디스는 높은 성능을 보여준다.
- 짧은 명령 처리 시간: 레디스는 많은 경우에 해시 테이블을 사용하여 O(1)의 시간으로 작업을 수행할 수 있다. (자료 구조에 따라서 추가적인 연산이 필요한 경우도 있음)
- 적은 컨텍스트 스위칭: 단일 스레드 모델은 작업을 중단하고 다른 작업을 시도하지 않기 때문에 컨텍스트 스위칭 비용을 피할 수 있다.
- 부하가 큰 작업에 대한 비동기 방식 지원: 백그라운드 스레드를 통해 비동기적으로 모든 데이터를 삭제하는 flushall async 등의 명령어를 사용할 수 있다.
- RAM에서 동작: 레디스는 RAM 위에서 동작하기 때문에 빠른 속도로 읽고 쓰기가 가능하다.
위와같은 동작으로 레디스는 아주 빠른 속도로 작업을 전환하는 동시성을 보장한다. (병렬성x)

I/O 멀티 플렉싱
레디스의 v6.0 부터는 입출력에 대한 멀티쓰레드-멀티플렉서가 추가되었다. (데이터베이스 연산 작업은 여전히 싱글 스레드로 이루어짐)
레디스는 RAM에 데이터를 저장하고 명령 처리의 시간이 매우 짧기 때문에 CPU가 병목지점이 아니라 네트워크 I/O가 주요 병목지점이었다.
I/O 멀티플렉서는 클라이언트가 Redis 서버에 연결하면 소켓 연결을 유지하면서 read/write가 발생할 때 이를 이벤트 루프로 전달하고 작업이 완료되면 연결을 끊는다.
이러한 멀티스레드 방식으로 I/O 요청에 대한 병목 현상이 줄어들어 성능이 개선되었다.
레디스의 백업 방식
레디스는 기본적으로 RAM위에서 동작하지만 메모리 데이터를 디스크에 저장하여 영속성을 확보할 수 있다.
RDB (Redis Database)
RDB 방식은 특정 시점에 메모리에 저장된 내용을 바이너리 파일로 디스크에 저장하는 것(snapshot)이다.
snapshot을 추출하는 것이 시간이 오래 걸리기 때문에 작업 도중 오류가 발생하면 모든 내용을 소실할 가능성이 있다. 하지만 한번 추출된 스냅샷을 복구하는데 AOF보다 짧은 시간이 들어간다.
AOF (Append Only File)
AOF 방식은 모든 read와 update에 대한 연산을 로그로 기록하고 이후 복구하는 방식이다.
모든 데이터 연산을 기록하고 복구할때는 이를 재현하기 때문에 시간이 오래걸린다. 하지만 RBD 방식보다 데이터를 복구시 예상되는 데이터 손실이 적어진다.
둘을 함께 사용할 경우 레디스 자체적으로 AOF 방식이 신뢰도가 높다고 판단하여 복구 우선도가 높다.
레디스 HA
데이터 샤딩 방식
레디스 클러스터는 16,384개의 해시 슬롯을 가지고 있으며, CRC16 해싱 알고리즘을 사용해서 키 값을 어떤 노드에 할당할지를 결정한다. 이 때 해시 슬롯은 저장소 노드의 담당 범위를 나타내며 그 자체가 저장소를 의미하지는 않는다.
예를 들어 A저장소가 1~8192까지의 슬롯을 담당하고 B 저장소가 8193 ~ 16,384까지의 슬롯을 담당한다고 했을때, CRC16의 계산 결과가 1000인 키는 저장소 A에 저장되고, 다른 키의 CRC16의 계산 결과가 마찬가지로 1000이라면 이것도 저장소 A에 저장한다. (클러스터링의 범주 기준으로 사용됨)
데이터 복제 방식
레디스는 비동기 방식으로 데이터를 복제한다.
클라이언트가 마스터 노드에 데이터를 입력한 뒤 마스터 노드가 클라이언트에게 완료된 작업을 내보낸다. 이후 마스터 노드는 복제본에 해당 내용을 전파한다. 이때 복제본에 내용을 전파하는 지연시간이 있기 때문에 순간적으로 데이터의 정합성이 깨질 수 있다.
WAIT이라는 명령어를 통해 동기적으로 복제할 수 있지만 실행 속도가 느려진다.
Redis Sentinel
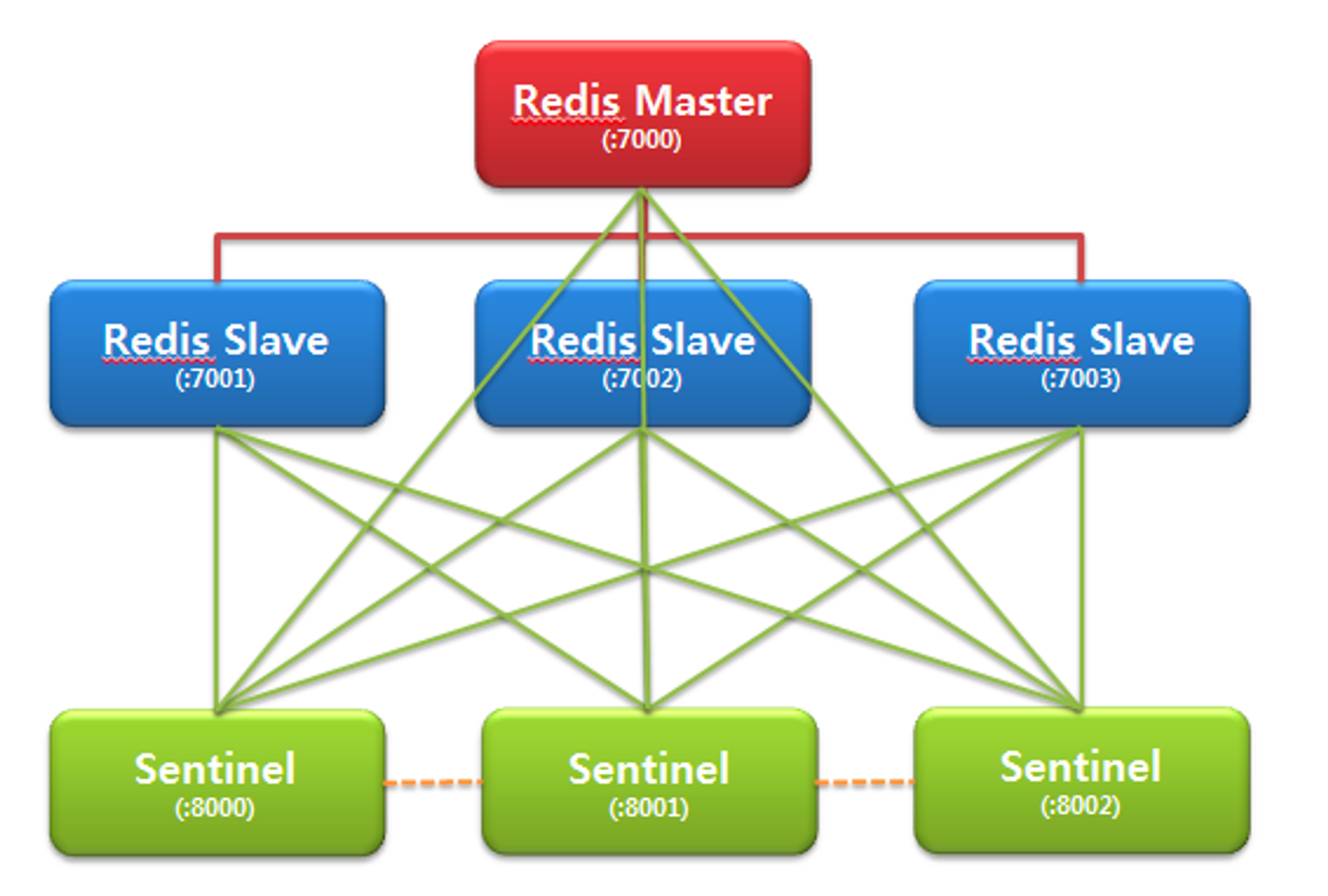
레디스의 고가용성 모드에는 sentinel과 cluster 방식 두가지가 있다.
sentinel 방식은 단일 master를 가지고 있는 master-slave 구조이다.
하나의 master가 쓰기 작업을 담당한다.
master에서 읽기 작업은 가능하지만 부하 분산을 위해 일반적으로 slave가 읽기 작업을 담당한다.
sentinel 방식의 특징은 다음과 같다.
- 샤딩 미사용: 각각의 slave 노드는 master 노드의 모든 데이터를 가지고 있다.
- sentinel에 의한 장애 감지: sentinel이라고 하는 감시 전용 노드를 통해서 장애를 탐지하고, 만약 master 노드에 장애가 생겼다면 slave 노드를 master로 승격 시킨다.
수동 승격 절차: 수동으로 승격 → slave 노드의 읽기 전용 풀기 → 레디스 입구를 복제본의 ID로 바꾸고 배포
Redis Cluster

cluster 방식은 여러개의 master 노드를 두고 데이터를 분산 저장하는 방식이다.
cluster에서는 여러개의 master와 slave 노드가 있으며 일반적으로 master 노드 하나 당 하나 이상의 slave 노드를 가진다.
sentinel과 마찬가지로 master에서 읽기 작업은 가능하지만 부하 분산을 위해 일반적으로 slave가 읽기 작업을 담당한다.
cluster 방식의 특징은 다음과 같다.
- 매시 네트워크: 모든 노드가 연결되어 서로가 제대로 동작하는지를 감시한다. 만약 master 노드가 제대로 동작하지 않는다면 slave 노드가 master 노드를 대체한다.
- 샤딩: 모든 데이터는 master 단위로 샤딩되고 해당 master 산하의 slave에 복제된다.
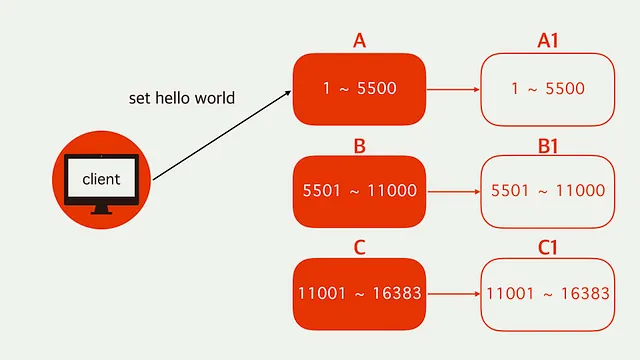
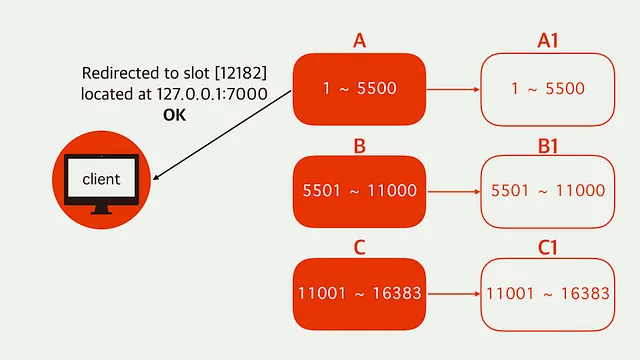
데이터가 분산 저장되기 때문에 올바른 노드를 찾아가야 할 필요성이 있다.
위의 그림과 같이 잘못된 노드(CRC16 해싱에 의해 정해진 slot)를 찾아가서 get, set 등의 요청을 하면 요청한 키가 다른 노드에 있다는 MOVED 응답을 반환하며, 클라이언트는 이러한 요청을 받고 올바른 노드의 주소로 다시 요청을 보낸다.
메모리에서 동작하기 때문에 OOME를 방지하기 위해 메모리를 최적화 하는 것도 중요하다.
레디스 메모리 최적화 방안
데이터 압축 저장
레디스는 자체적으로 압축 기능을 제공하지 않지만, 애플리케이션 레벨에서 데이터 압축을 적용할 수 있다. snappy나 zlib 등을 이용해서 압축한 데이터를 value 값으로 저장하는 것으로 메모리를 아낄 수 있다.
ROF (Redis Object Frequency)
Redis Object Frequency (ROF)는 레디스에서 Least Frequently Used (LFU) 알고리즘을 구현한 것으로 자주 사용되지 않는 키를 우선적으로 제거하여 효율적인 메모리 사용을 할 수 있다.
자료구조 최적화
list 대신 Ziplist(작은 크기의 리스트나 해시를 저장할 때 사용되는 압축된 자료구조)를 사용 하거나, set 대신 intset(작은 집합을 저장할 때 사용되는 자료구조)를 사용하는 등 자료구조를 통해 메모리를 최적화 할 수 있다.
추가 QnA
Q. Redis의 Master 노드에서 장애가 난 다음 승격된 Slave 노드가 다시 장애를 일으키면?
A. 다음 Slave 노드가 있으면 승격 시키고, 없으면 해당 슬롯 범위에 대한 요청 처리가 일시적으로 중단된다. 이후 수동으로 노드 추가 및 복구 작업을 수행해야 한다. 하지만 중간에 Master 노드가 되살아나는 경우도 있는데 이 때는 되살아난 Master 노드가 Slave 노드가 된다. 출처: https://www.essential2189.dev/what-is-redis
Q. RDB와 AOF 중 어떤 방식이 더 나은지?
A. 상황에 따라 다르다. 데이터의 빠른 복구가 더 중요하다면 RDB를 사용하고 더 많은 데이터를 안전하게 백업해야 한다면 AOF를 사용하는 것이 좋다. 둘 다 사용한다면 시스템적으로 AOF가 우선적으로 복구된다.
Q. Redis의 dict 자료구조가 어떻게 해시 충돌을 처리하는지 설명.
A. 해시 체이닝으로 충돌을 해결한다. redis/src/dict.c에 주석으로 "collisions are handled by chaining."이라 적혀있음 출처: https://github.com/redis/redis/blob/unstable/src/dict.c
Q. RDB 스냅샷을 추출하는 동안 발생할 수 있는 문제와 이를 최소화할 수 있는 방법이 있는지?
A. 백그라운드 스냅샷(bgsave)을 사용하고, 스냅샷 주기를 최적화하는 것으로 문제를 완화할 수 있다. 출처: https://velog.io/@lhs8701/Redis-%EC%A0%95%EB%B3%B5%EA%B8%B0-1%ED%8E%B8-%EB%B0%B1%EC%97%85
Q. AOF 파일이 시간이 지남에 따라 커질 수 있는데, 이를 관리하는 방법은?
A. AOF 리라이트(rewrite)를 통해 파일 크기를 줄일 수 있다. 출처: Redis에서 AOF Rewrite 기법의 오버헤드 분석(한국정보기술학회논문지, Volume 15, Number 3, 1-10 pp.)
Q. Redis Sentinel 방식에서 Sentinel 노드가 장애를 탐지하는 메커니즘은?
A. Sentinal에서 주기적으로 Master에게 PING과 INFO 명령의 응답이 설정한 값 이상동안 오지 않는다면 주관적 다운으로 인지하며 설정한 정족수(Quorum) 이상의 Sentinal에서 해당 Master가 다운되었다고 인지하면 객관적 다운으로 인지한다.
출처: https://junuuu.tistory.com/768
레디스에서 일반적으로 Quorum은 과반수이다.
Q. Redis Cluster 방식에서 장애를 탐지하는 메커니즘은?
A. Gossip 프로토콜을 이용해서 주기적으로 무작위의 주변 노드와 정보를 교환한다. 이때 정족수(Quorum) 이상의 노드가 특정 노드가 장애상태라고 판단하면 해당 노드는 장애 상태로 판별된다.
출처: https://medium.com/@wellsy001012/redis-cluster%EC%9D%98-gossip-message-%EC%9E%A5%EC%95%A0-%EA%B0%90%EC%A7%80-failover-6541471c8c99
Reference:
A Crash Course in Redis
Redis는 왜 빠를까?
[Redis Documentation #2] 레디스 클러스터 튜토리얼
It is possible for only the Redis master instances to handle all reads and writes, and for the slaves to be used only for failover?
'Computer science > Database' 카테고리의 다른 글
| 데이터베이스 격리 수준 (0) | 2024.08.28 |
|---|---|
| MongoDB의 migration과 cursor (0) | 2023.12.14 |
| 이상현상과 트랜잭션의 격리 수준 (0) | 2023.09.12 |
| ACID 원칙이란? (0) | 2023.09.12 |
| 데이터베이스의 원리와 응용 8 (0) | 2022.04.09 |